Scroll down for Interactive Code Environment 👇
In the second part of my Deep Learning Foundations series, I’m peeling back the layers on one of the most fundamental units of neural networks: the single neuron. This dive is all about breaking down how a neuron takes inputs, works its magic through weights and biases, and pops out an output that’s shaped by something called the ReLU function.
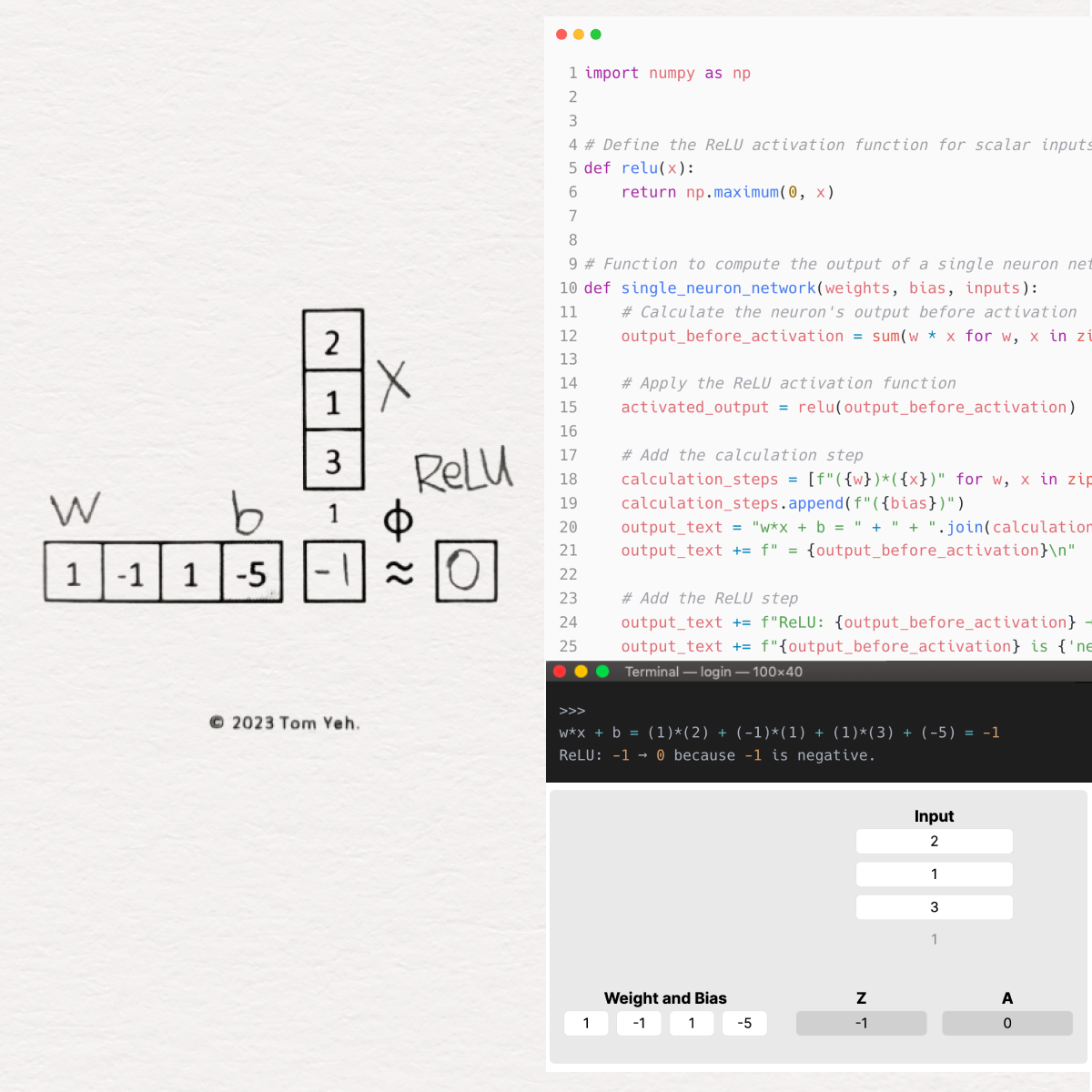
Single Neuron: Breaking It Down
At its heart, a single neuron is a marvel of simplicity and power. It’s where the rubber meets the road in neural networks. Let’s talk about what happens inside this tiny powerhouse.
Walking Through the Code
I’ve cooked up a Python script that mirrors the essential function of a single neuron, enhanced with the ReLU activation. Let’s dive into a step-by-step walkthrough of the code that simulates a single neuron’s functionality, focusing on the ReLU activation function. This practical example illuminates the foundational concepts previously discussed.
-
Kicking Off with NumPy:
- I start by importing
numpyasnp, leveraging its robust numerical computation tools, crucial for handling arrays with ease. NumPy is indispensable for mathematical operations in Python, especially within the deep learning realm.
- I start by importing
-
Bringing the ReLU Function to Life:
- The
relu(x)function embodies the ReLU (Rectified Linear Unit) activation function. It’s straightforward yet powerful: it returnsxifxis positive, and zero otherwise. This function is key for introducing non-linearity, enabling neural networks to tackle complex problems.
- The
-
Simulating the Neuron:
- The heart of our discussion, the
single_neuron_networkfunction, simulates a neuron at work. It takesweights,bias, andinputsas inputs.- Weights and Inputs: Here, each input is multiplied by its corresponding weight. The weights are the knobs and dials of the neural network, adjusted during training to hone the network’s accuracy.
- Bias: Adding the bias to the sum of weighted inputs provides an extra layer of flexibility, allowing the neuron to fine-tune its output.
- The heart of our discussion, the
-
Output Calculation Before Activation:
- This step involves calculating the neuron’s output before any activation is applied, by summing the products of inputs with their respective weights and adding the bias. This represents the linear aspect of the neuron’s operation.
-
Applying ReLU Activation:
- The output from the linear calculation is then fed through the ReLU function. This is where non-linearity comes into play, empowering the network with the ability to learn and model intricate patterns.
-
Detailing the Calculation Steps:
- For clarity and educational value, I construct a string outlining each step: multiplying inputs by weights, adding the bias, and the outcome of applying ReLU. This transparency is invaluable for understanding and debugging.
-
Revealing the Results:
- The culmination of this process is printing out the calculation steps, displaying the output before and after the ReLU function’s application.
-
Executing the Simulation:
- With
inputs,weights, andbiasall set, I execute thesingle_neuron_networkfunction. This run simulates the neuron in action, applying the discussed steps to output the results of a single neuron after ReLU activation.
- With
This code walkthrough demystifies the basic operations underlying neural network functionality. Breaking down the neuron’s process into digestible steps enhances the grasp of how neural networks process inputs to produce outputs, paving the way towards understanding more complex architectures.
Interactive Code Environment
Original Inspiration
This journey was sparked by the insightful exercises created by Dr. Tom Yeh for his graduate courses at the University of Colorado Boulder. He’s a big advocate for hands-on learning, and so am I. After realizing the scarcity of practical exercises in deep learning, he took it upon himself to develop a set that covers everything from basic concepts like the one discussed today to more advanced topics. His dedication to hands-on learning has been a huge inspiration to me.
Conclusion
Understanding how a single neuron works lays the foundation for everything else in neural networks. Today, we’ve covered the ReLU function’s role in transforming a neuron’s output. In my next post, I’ll be taking this foundation and building on it, moving from single neurons to how they connect and interact in larger networks. Plus, I’ve include a link to a LinkedIn post where we can dive into discussions and share thoughts.
- Last Post: Intro to Matrix Multiplication Basics
- Next Post: Unraveling Four-Neuron Networks
LinkedIn Post: Coding by Hand: Single Neuron Networks in Python

About Jeremy London
Jeremy from Denver: AI/ML engineer with Startup & Lockheed Martin experience, passionate about LLMs & cloud tech. Loves cooking, guitar, & snowboarding. Full Stack AI Engineer by day, Python enthusiast by night. Expert in MLOps, Kubernetes, committed to ethical AI.